Open Data Engine Origins
Survloop began as database design software based upon recommendations presented in Database Design for Mere Mortals: A Hands-On Guide to Relational Database Design (3rd Edition), by Michael J. Hernandez. These web-based tools to document database tables and field specifications were used for six months to design a database perhaps close to the complexity of TurboTax®.
Survloop can export MYSQL and Laravel Migration files to install the designed database. It's worth noting that the field specifications are very thorough, but only some of the details are currently enforced when auto-installing the tables through Survloop.
Then we wanted to start prototyping the system, looked around at open source options, and couldn't find any we could trust would have most of the features we would need. So I began prototyping what the survey might look like, and couldn't help but start generalizing the algorithm. So the database design engine now had a related multi-page-survey-generation engine.
Branching Trees Create Content
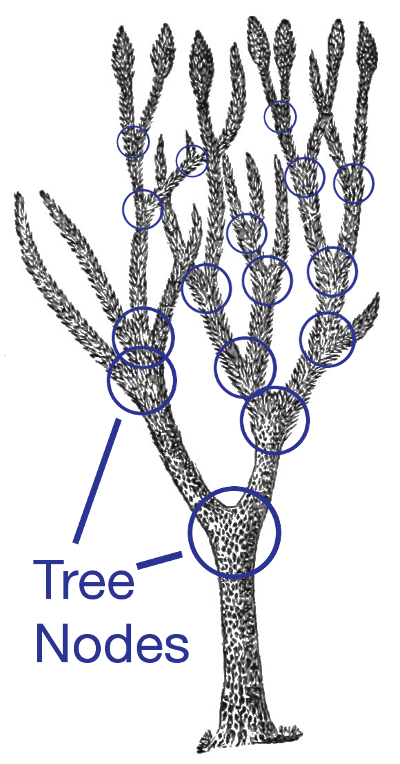
The survey specifications are stored in branching trees, similar to a "choose your own adventure" book.
The spots where branches (or paths) separate from each other are often called
nodes.
Most nodes in this tree represent either a single question to ask the user, instructions, or a
Some nodes have children that respond to certain user choices by revealing more questions on the page. Many options are provided when editing a node, and most questions can be easily set up to automatically store user responses to a specific field in the database.
A few nodes are "branches" which wrap multiple pages and/or sub-branches, and are used more internally to define main sections and subsections of the entire process. These often help define the navigation menu provided for the user.
Some nodes are marked as the root node of a loop. The children of a loop's root node will loop through multiple records of one collection of data. They serve one or more questions, pages, or whole branches, for each record. They can be set up to allow the user to add new records as part of that process, or cycle through previously entered data sets.
The admin interfaces for managing these trees have not yet been given much improvement. But in the map of each tree, the left side previews the meat of what the user will see, and the right side shows where the response is stored into the database design.
The public-facing survey generation aspects of the code base have been the most heavily tested, developed, and polished. One long-term goal is to replace all of Survloop's admin tools with Survloop-generated forms and reports. It would be very cool to evolve it all the way into a self-replicating GUI.
Content Management System (CMS)
There was a need for creating super simple static pages like for a privacy policy directly tied to the survey. We could've hosted it elsewhere, but it became clear how easy it would be to reuse the survey-generator to produce simpler pages.
The infrastructure was also already in place to print reports for the data collected, with the help of the same database design specifications. And so, Survloop's mission crept into including more features offered by any CMS, though many of these features aren't terribly evolved or polished yet.
Currently, you need to be a web developer to effectively install and manage software powered by Survloop. Within another five years, hopefully, all the core functionality to create and manage an open data web app will be easy enough for the common modern mind.
Survloop vs Client Installations
On its own, you could install Survloop and only use it to design a database and document its specifications. You could generate MYSQL commands to create all the tables. You could also use all of the survey and reporting features that are already built into Survloop.
But if you want to get more advanced, you'll want to create a client/custom installation that extends the Survloop package and engine. This includes extended versions of the main tree-traversing area of the codebase, admin area, and data searching functionality.
For example, it also allows you to override specific nodes within any branching tree in your system. This way you can get as complicated as you want with both your logic and presentation.
So that's how we got here, and other documentation will help introduce you to more specific aspects of Survloop, an open data engine used to create, fill, and share complex databases. Thanks so much!
Documentation Overview
How To Install Survloop
Survloop Codebase Orientation
- What Is Survloop?
- Folders, Files, & Classes
- Developer Workflows
- How A Basic Page Loads